
|
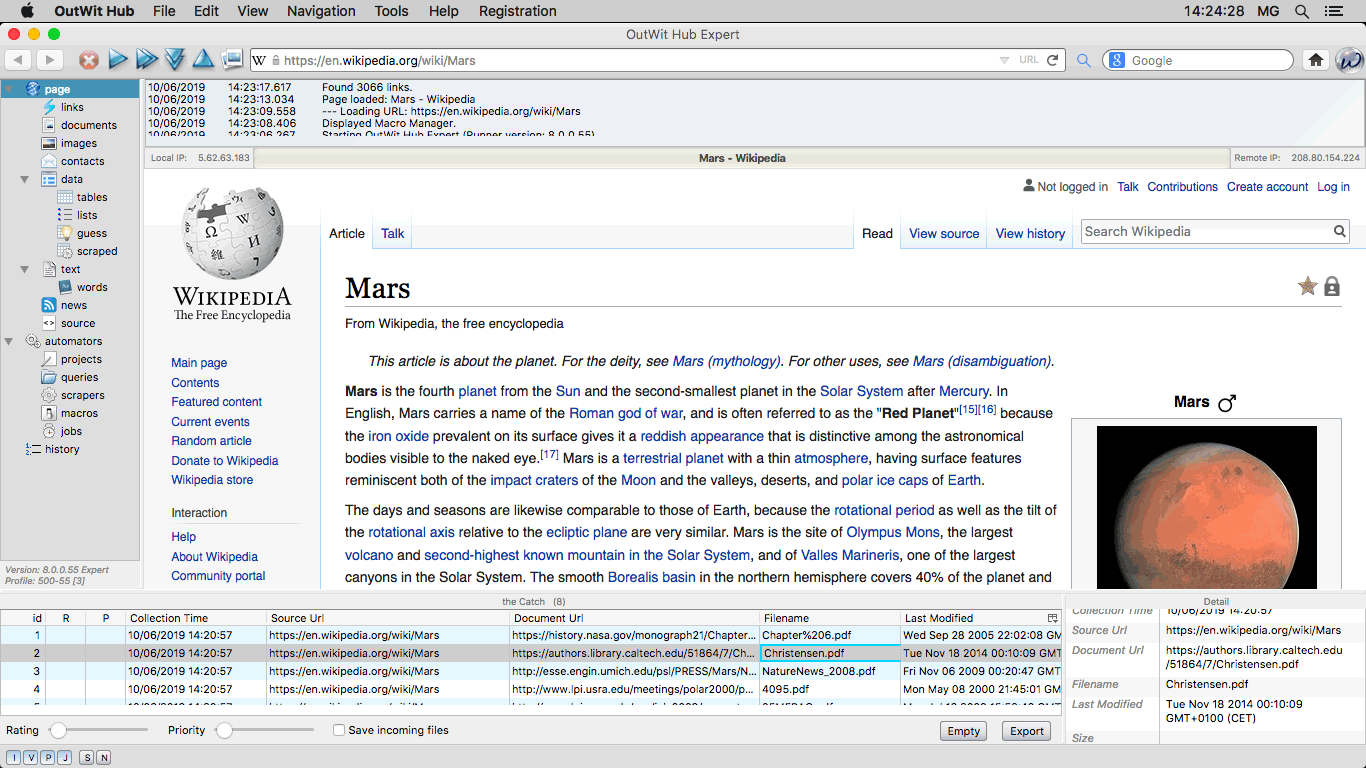
The Page View Among many other things, OutWit Hub is a browser: the page view allows you
to simply navigate, as you would with any Web browser, to the sites containing the
data you wish to extract. |
 |
|
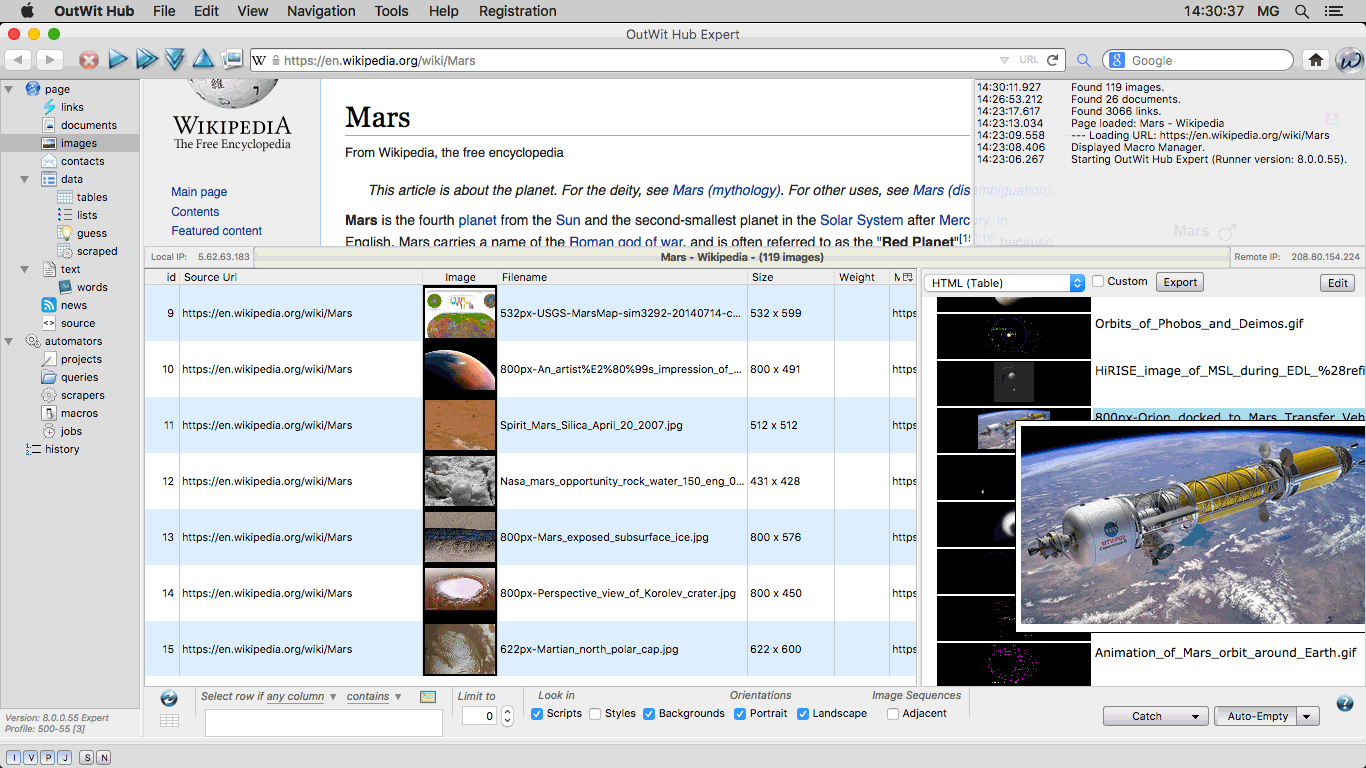
The Images View OutWit Hub views are accessible through the left side panel. |
 |
|
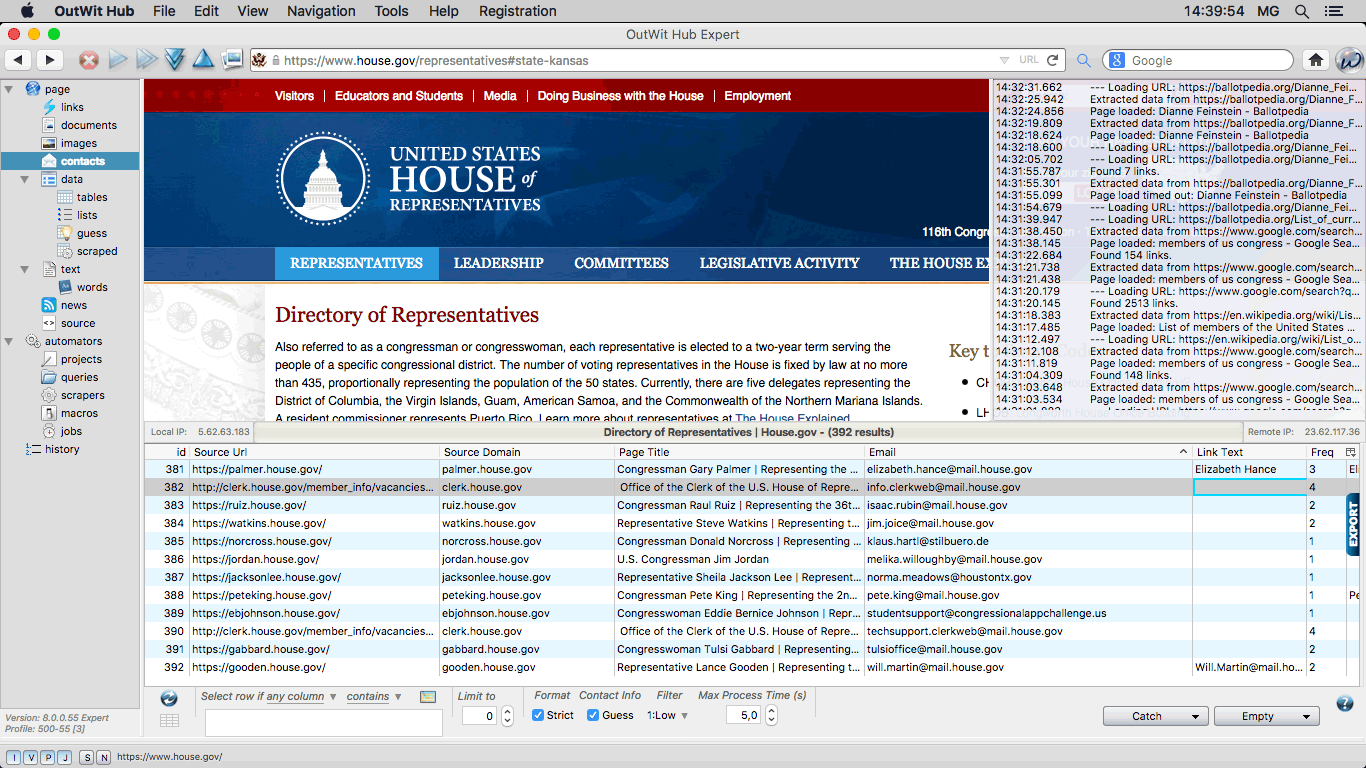
The Contacts View When applying this extractor, the program scans the source code of the current page
using a number of different strategies to recognize contact records with as many
fields as possible: email address, phone numbers, physical address, contact name,
photo portrait, company, meta description, keywords, etc.. |
 |
|
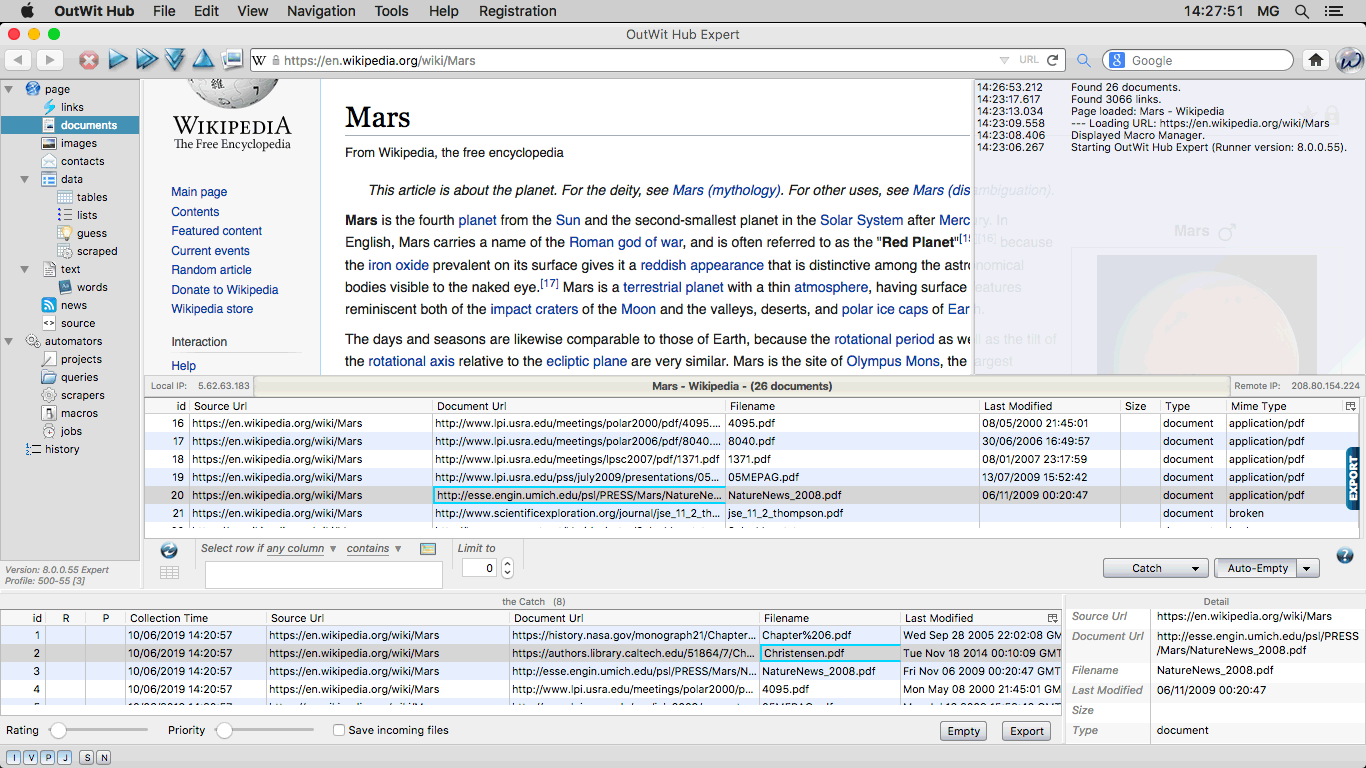
The Documents View The documents view contains the URLs of document files of various formats
like PDF, CSV, Excel, Word, PowerPoint, etc., that were found in the current page.
|
 |
|
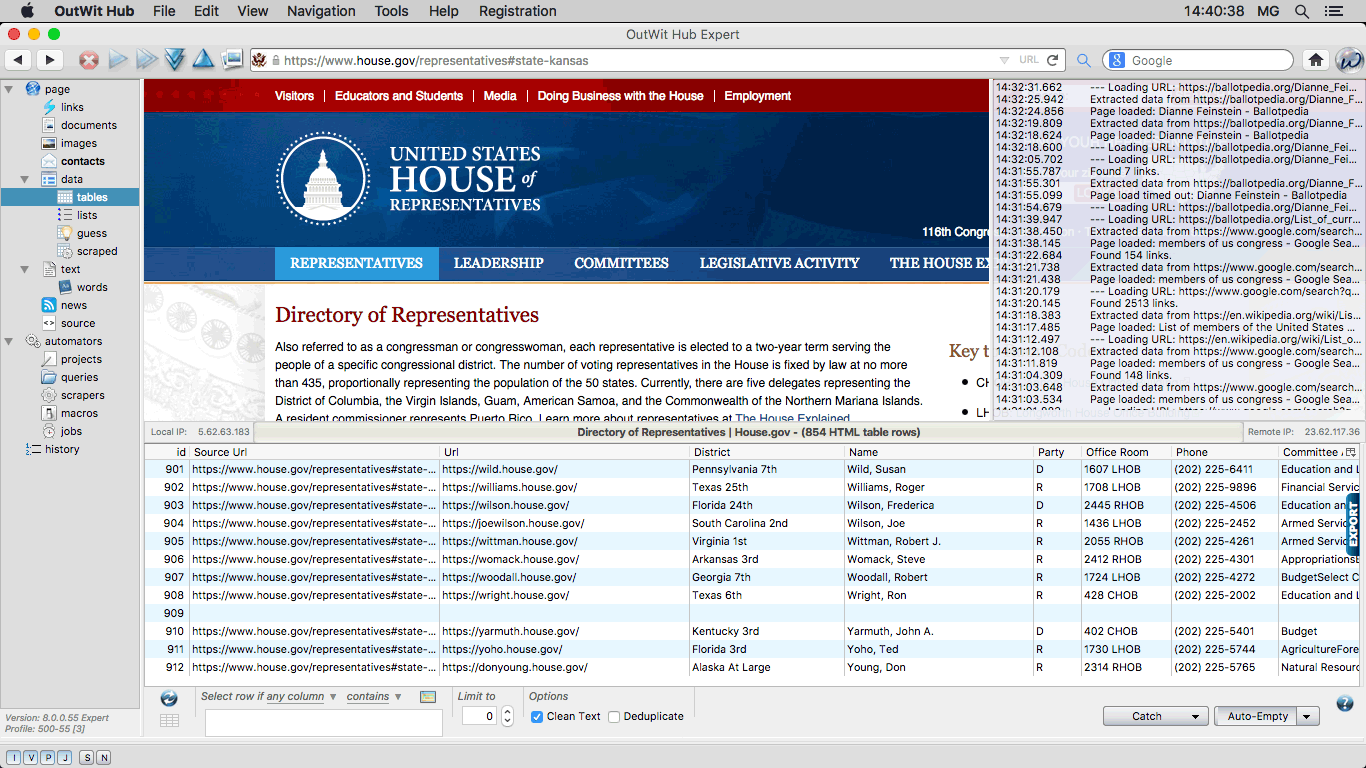
The Tables View Extracts and displays the data presented as HTML tables in the current page or in a list of pages, inserting the most pertinent URL of each row before the first column of data in the datasheet. |
 |
|
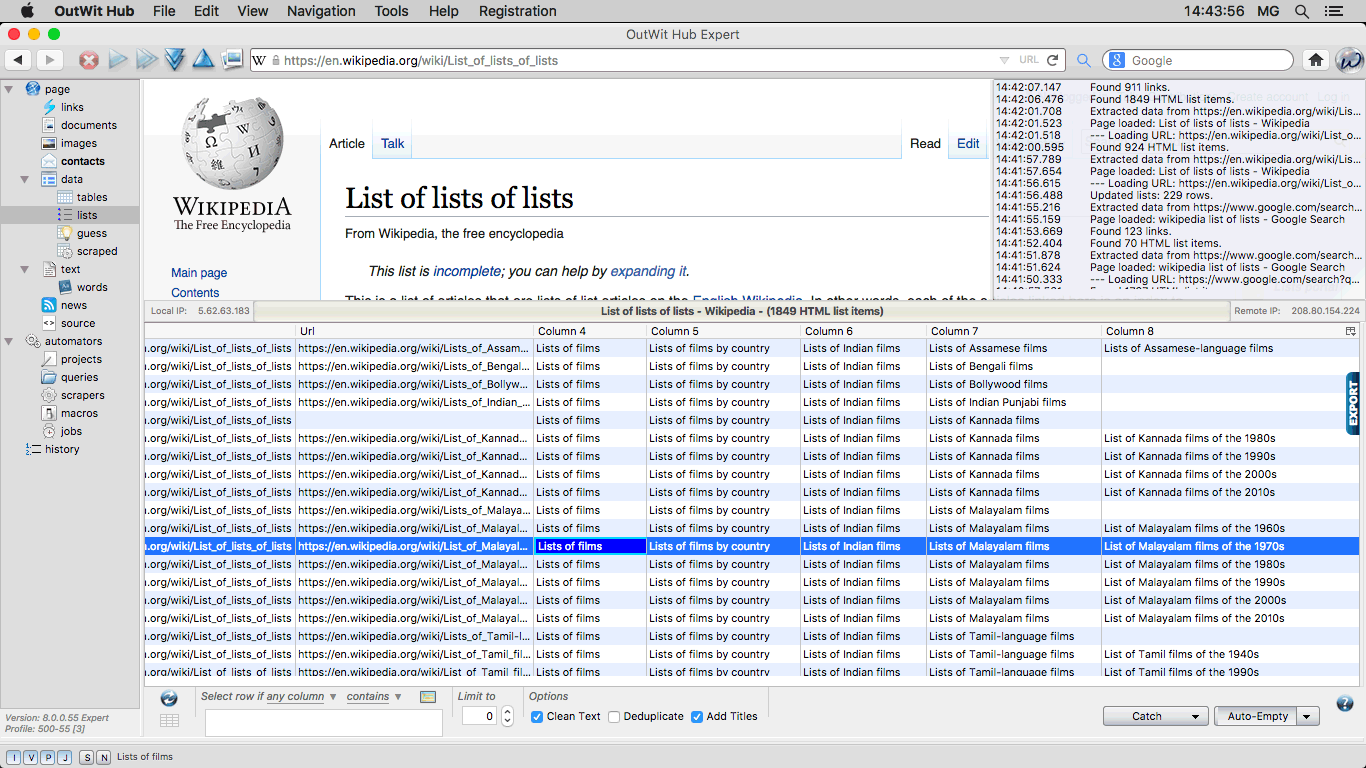
The List View Extracts and displays the data presented as HTML lists in the current page or in a list of pages, keeping the hierarchical organization of the lists and inserting the most pertinent URL of each row as the first column in the datasheet. |
 |
|
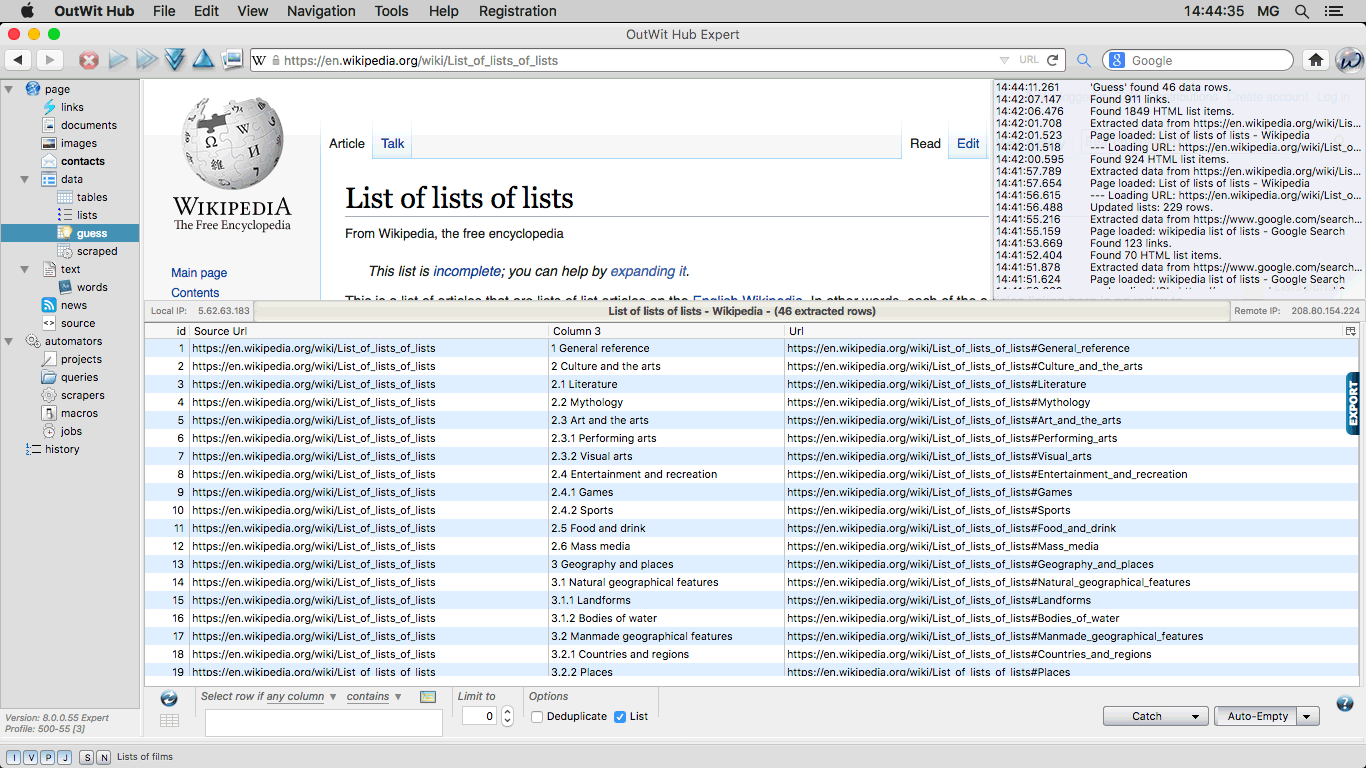
The Guess View When the data in the Webpage is not presented as an HTML table or list and before you
create a custom scraper for this page (see next view), OutWit Hub can try to guess
the scructure of the data and do the extraction automatically. |
 |
|
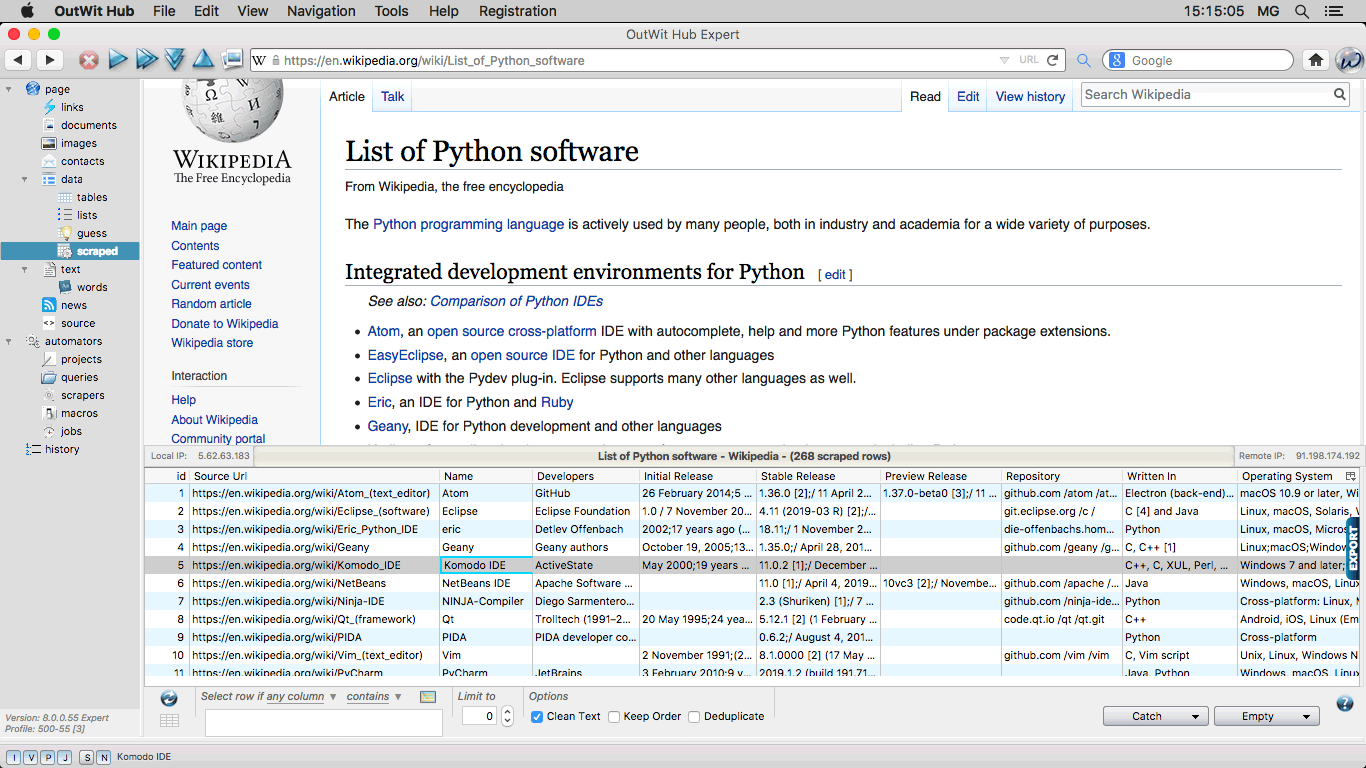
The Scraped View This is the view that receives the data extracted by custom scrapers. |
 |
|
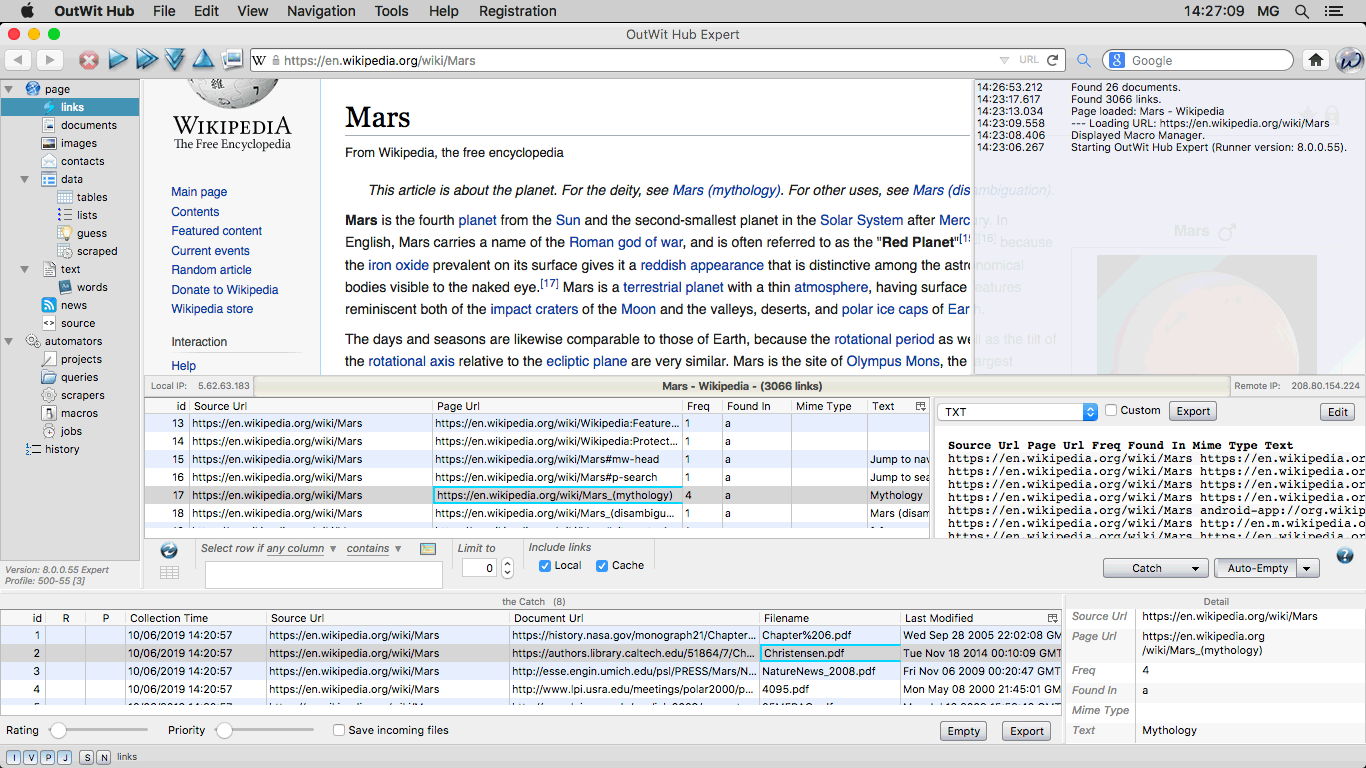
The Links View The links view contains all the Web links found in the current
page. |
 |
|
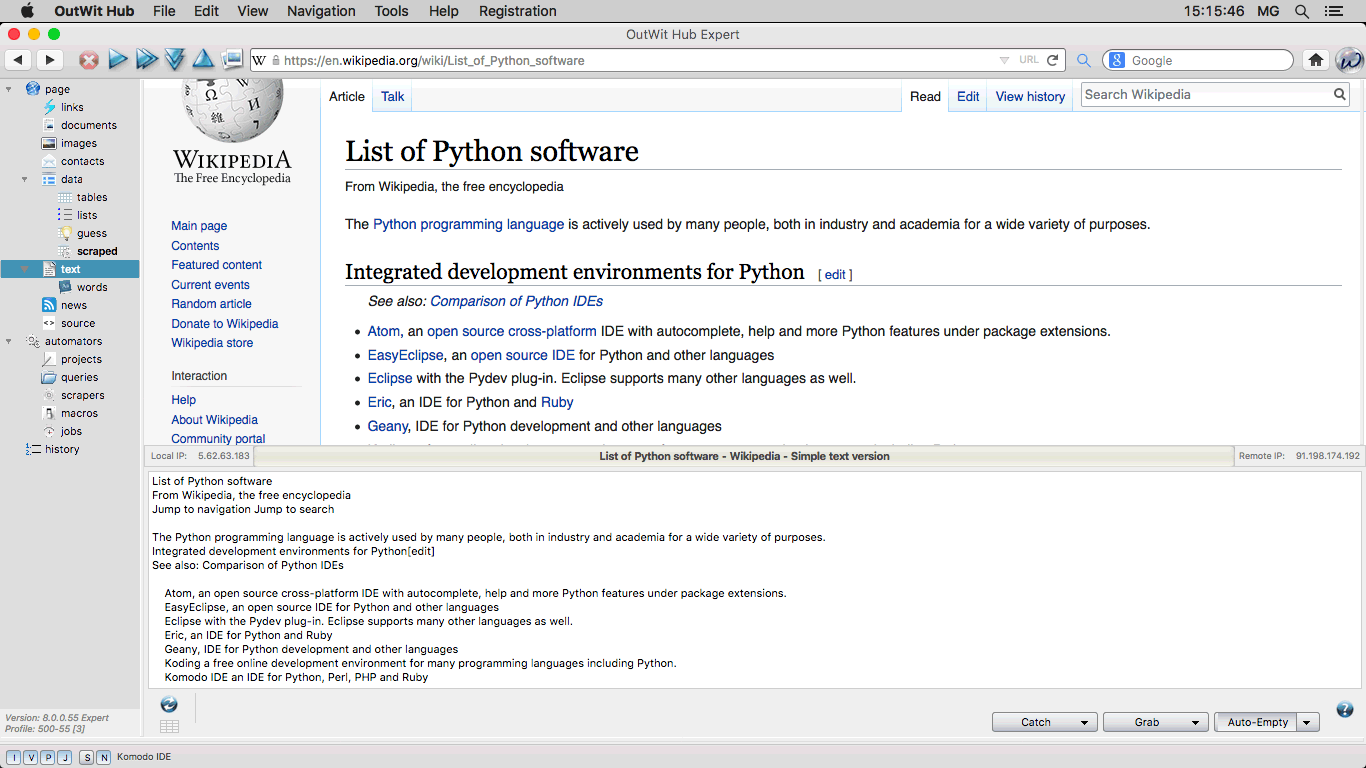
The Text View Displays the content of the current page as simple text. |
 |
|
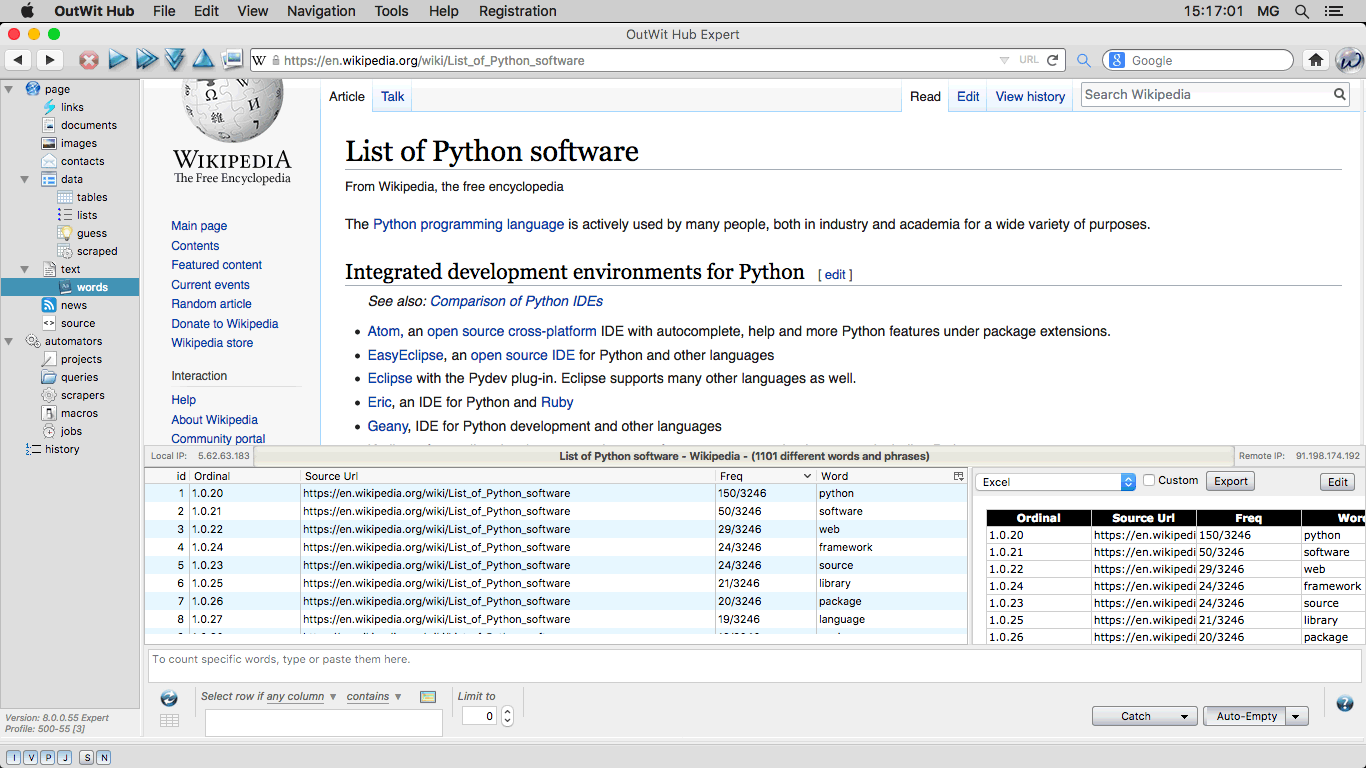
The Words View Presents all the different words and recurring groups of two, three or four words, and sorts them by frequency in the current page or in the series of pages that were explored while the words extractor was active. |
 |
|
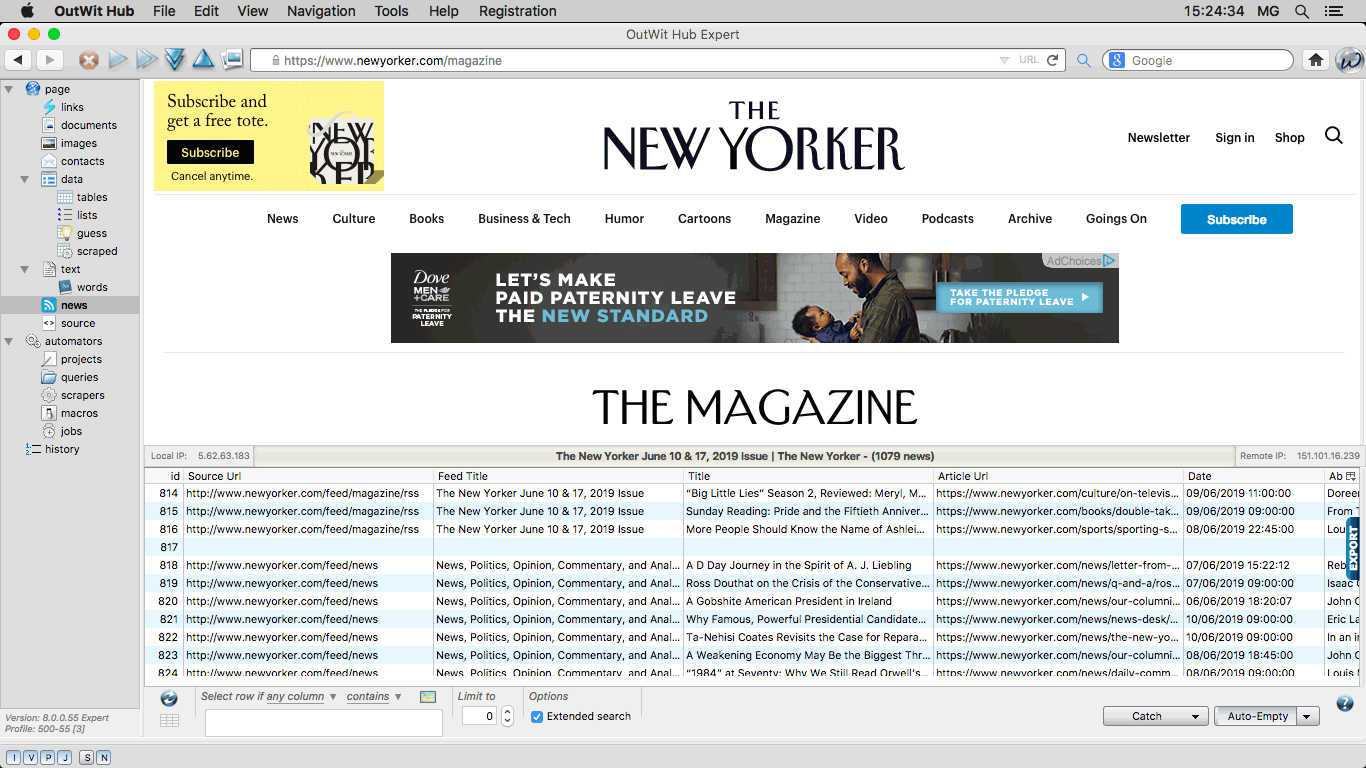
The News View Explores the current page and pertinent links within it, to find RSS feeds and display them as records in the view's datasheet. |
 |
|
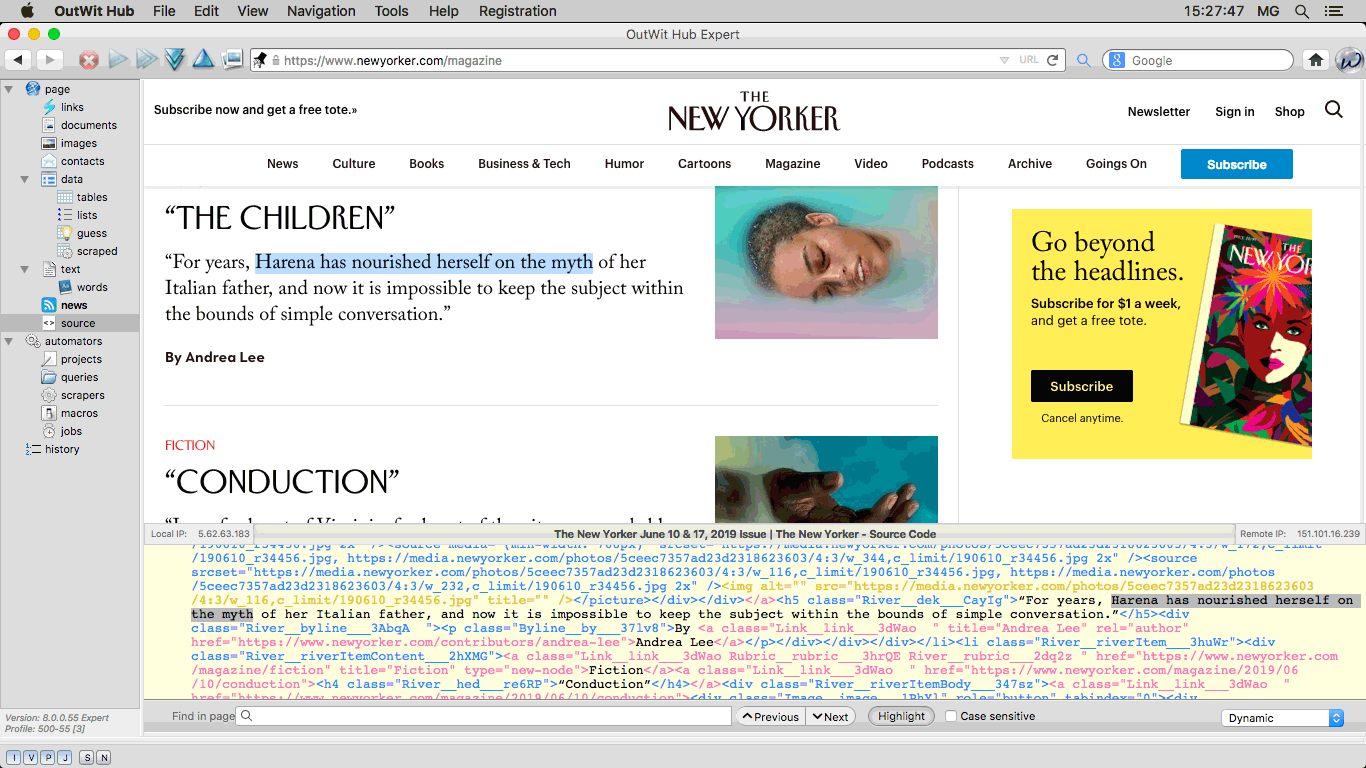
The Source View OutWit Hub source view can display three different types of source code that
you can use for scraping the current page, depending on the type of the site (and of
the OutWit Hub edition you are using). |
 |
|
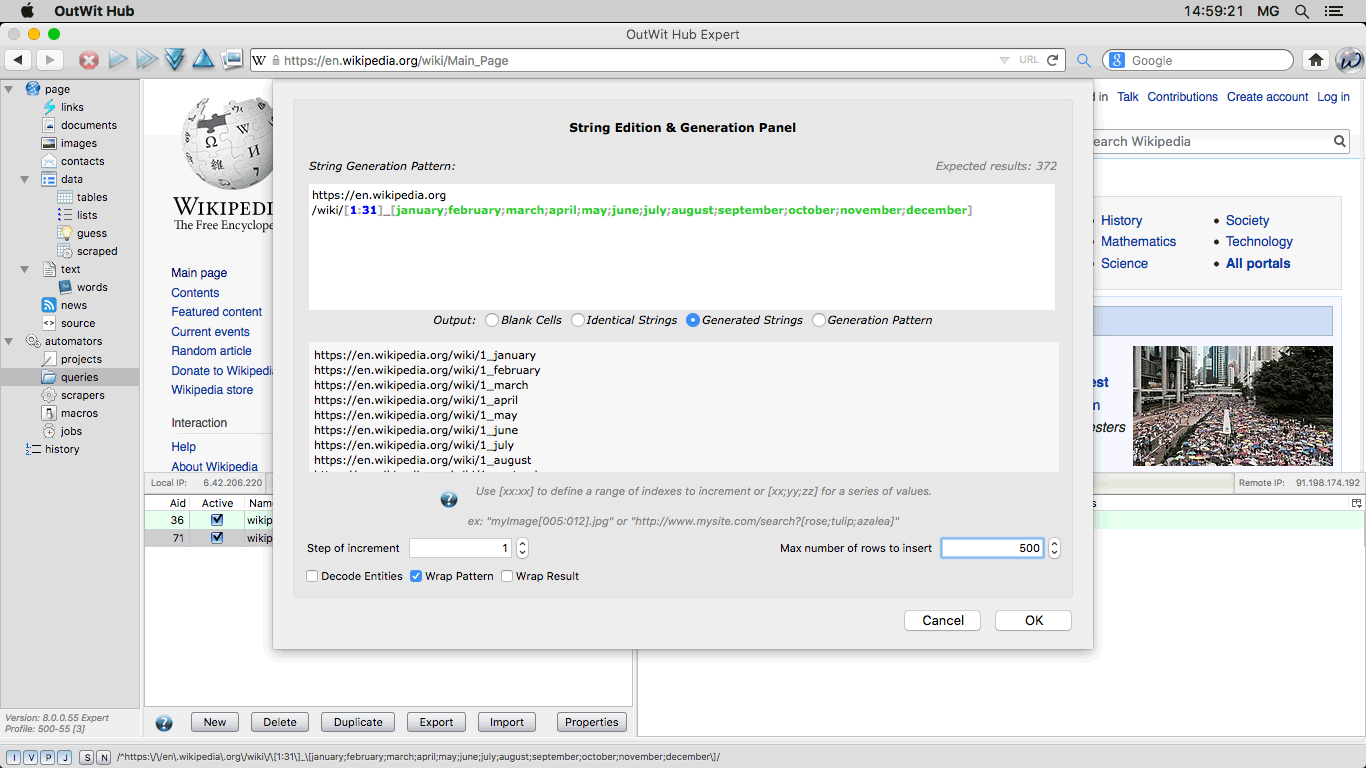
The String Generation Panel The String Generation Panel is a string editor with which you can generate, edit URLs or any other series of strings using a simple syntax to define ranges of numbers or letters, lists of values, etc. |
 |
|
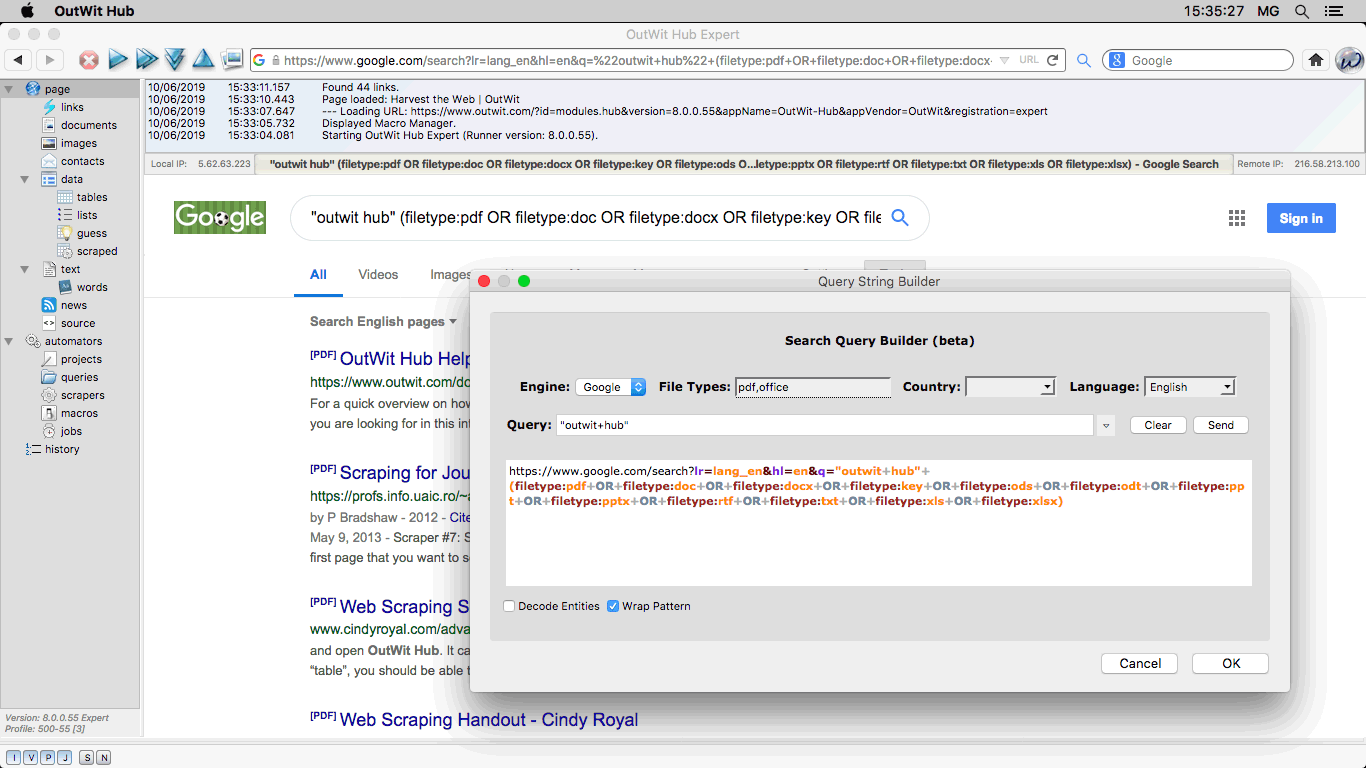
The Search Query Builder Added in version 8, the Search Query Builder allows you to generate, edit and send multiple-criteria search URLs for the most used search engines. (Available in the Expert and Enterprise editions.) |
 |